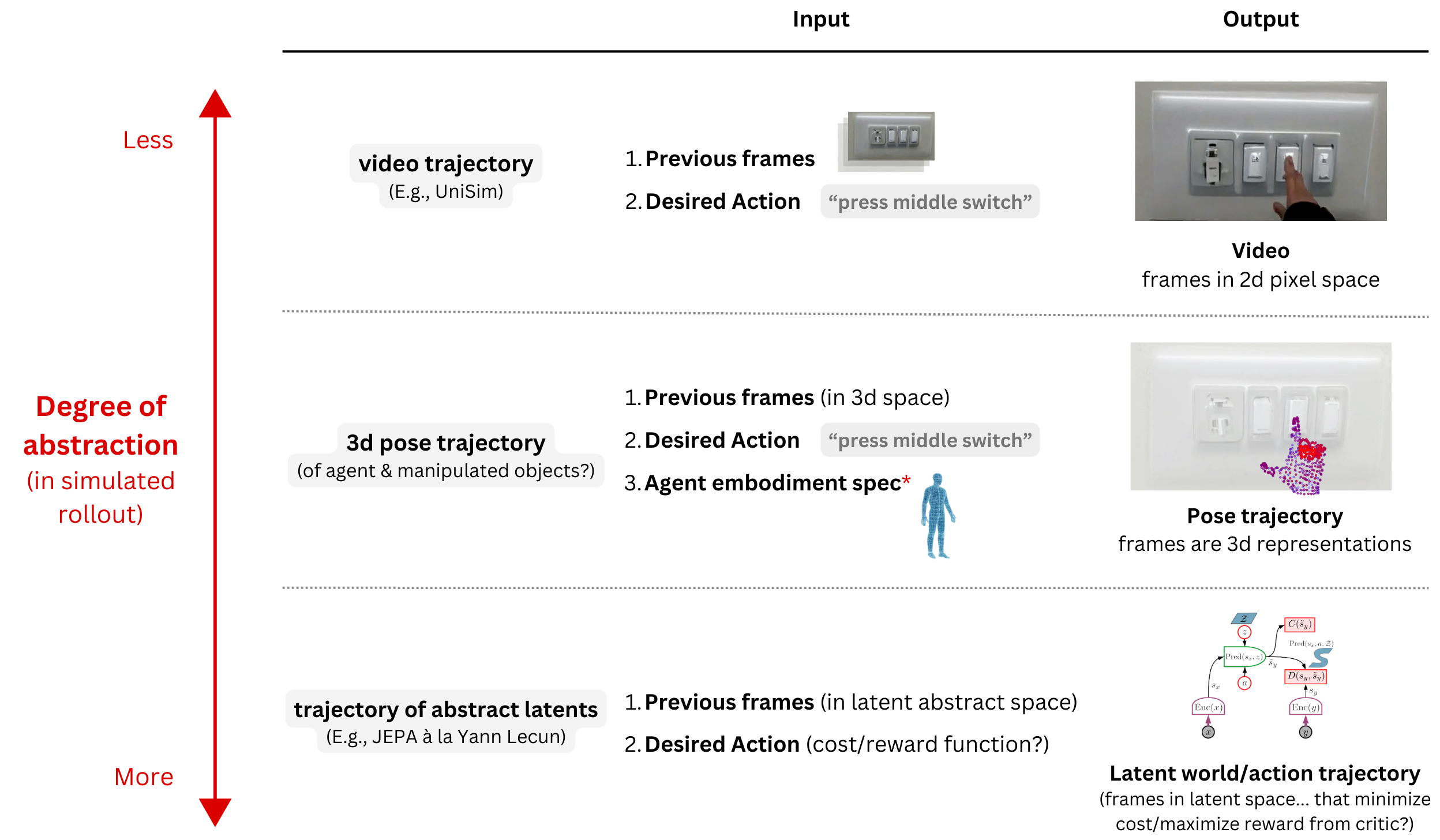
What is the proper level of I/O abstraction in world models (that generate simulated rollouts)?
Sonny George
January 10, 2025
As excitement builds around the idea of 'planning with simulated rollouts,' an open question remains regarding the most useful methods and degrees of abstraction in world model I/O spaces.
Video is an intuitive I/O space for generating simulated rollouts and contains high levels of detail/information (a picture is worth a thousand words). If we can generate realistic video, then simulating rollouts with video will indeed be viable. There is a lot of justified hype here. (See e.g., UniSim or Genie)
However, could much of video's pixel-by-pixel details be unnecessary for basic action—creating, at best, potentially expensive prediction overhead, and at worst, SGD distraction that prevents the learning of anything useful for long-tail and OOD scenarios? For instance, video models are often great at generating small details (e.g., textures) while struggling with higher-level dynamics (e.g., maintaining the physical coherence of a dynamic object).
Can we map internet-scale video data into a more appropriately abstracted representation space with minimal superfluous detail for basic action? Recently, Yann Lecun seems to be of the opinion that doing so is not only feasible, but also necessary for "autonomous machine intelligence" (see Lecun et. al's V-JEPA or alternatively, as an example of an RL algorithm that simulates rollouts in a latent space, DayDreamer).
Roboticists are essentially doing a version of this when they, before learning control policies, distill image/lidar data into assortments of pertinent 3d representations (maps, way points, point clouds, voxels, etc). Similarly, could action trajectories in internet-scale video be converted into consistently sensical and sufficiently informative 3d representations (e.g., with techniques like 3d scene reconstruction and pose estimation)?
Whether mapping video data for world model training to (1) (an assortment of?) 3d representations or (2) some other representation space with a theoretically higher (relevant-) signal-to-noise ratio, what stands to be gained/lost?
Could mapping massive video datasets into 3d trajectory representations and using them to train next-state-predicting world models have other downstream benefits? E.g.,
(1) Easier inference of embodiment-specific controls (by generating outputs that are already 3d representations of target poses)
(2) Cross-embodiment positive learning transfer? (perhaps the generation of any-embodiment outputs could be learned by conditioning generation on an embodiment specification*)
(3) Ability to incorporate physics-informed inductive biases (e.g., loss penalties for volumetric or joint-range impossibilities)
(4) Enablement of interpretable safety measures (e.g., preventing generations with potential collisions that approach a force threshold)